消息队列调研
消息系统简介
本次主要调研业界使用广泛的两款消息队列——RabbitMQ, Kafka, 以及阿里云的提供的两个服务, MNS和ONS.
RabbitMQ
RabbitMQ 是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
阿里云MNS
阿里云消息服务(Message Service,原MQS)是阿里云唯一商用的消息中间件服务。与传统的消息中间件不同,消息服务一开始就是基于阿里云自主研发的飞天分布式系统来设计和实现,具有大规模,高可靠、高并发访问和超强消息堆积能力的特点。消息服务API采用HTTP RESTful标准,接入方便,跨网络能力强;已全面接入资源访问控制服务(RAM)、专有网络(VPC),支持各种安全访问控制;接入云监控,提供完善的监控及报警机制。消息服务提供丰富的SDK、解决方案、最佳实践和7x24小时的技术支持,帮助应用开发者在应用组件之间自由地传递数据和构建松耦合、分布式、高可用系统。
阿里云ONS / RocketMQ
消息队列(Message Queue,简称MQ)是企业级互联网架构的核心服务,基于高可用分布式集群技术,搭建了包括发布订阅、接入、管理、监控报警等一套完整的高性能消息云服务,帮您实现分布式计算场景中所有异步解耦功能。经过多年积累,在交易、商品、营销等核心链路包括在双11场景下都有广泛使用,服务于阿里内部上千个核心应用,每天消息量达上千亿条,MQ由阿里巴巴集团中间件技术部自主研发,是原汁原味的阿里集团中间件技术精华之沉淀。
Kafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡.
Kafka的用户中包括LinkedIn, Yahoo, Twitter, Uber, PayPal, Airbnb, Tumblr等, 被用于日志收集, 离线分析, 实时分析, 消息管道等, 详情见 Powerd By Kafka
Kafka官方提供了Java版本的客户端API, Kafka社区产生了多种语言的客户端, 包括PHP, Python, Go, C/C++, Ruby, NodeJS等, 详情见 Kafka 客户端列表
Kafka Broker较为轻量, 不保存consumer的消费进度, 由consumer自己控制。 因此使用起来非常灵活, 可以针对不同场景定制不同的消费服务.
- Exactly Once: 消费且仅消费一次
- 回溯数据, 进行重复消费
目前Kafka的管理界面不友好, 官方只给了命令行工具. 通过命令行工具能简单地查看和操作Topic. Yahoo开源了自己的Kafka Web管理界面 Kafka-Manager, 但不支持最新的0.9.0版本的部分功能.
Kafka, RabbitMQ, MNS, ONS对比
| – | Kafka | RabbitMQ | MNS | ONS | |
|---|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Alibaba | Alibaba | |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟,公测中 | |
| 特点 | 充分考虑消息堆积因素,认为 consumer 不一定处于 alive 状态;考虑各个角色的分布式; 为追求吞吐量设计;被多家公司和多个开源项目使用 | 由于Erlang语言的并发能力,性能很好, 支持多种协议,重量级系统 | 消息服务API采用HTTP RESTful标准,接入方便,跨网络能力强 | 高性能, 支持数据海量堆积, 支持主动推送 | |
| 授权方式 | 开源 | 开源 | 商业 | 商业,有对应的开源项目RocketMQ | |
| 开发语言 | Scala&Java | Erlang | Java | Java | |
| 客户端支持语言 | 官方支持Java, 开源社区有多语言版本, 如PHP, Python, Go, C/C++, Ruby, NodeJS等编程语言, 详见 Kafka 客户端列表 | 官方支持Erlang, Java, Ruby等, 社区产出多种语言API,详见RabbitMQ客户端&开发工具 | Java, C++, Python, C#, PHP, Node.js(非官方), Golang(非官方) | Java, C/C++, C#, PHP | |
| 协议支持 | 自有协议,社区封装了HTTP协议支持 | 多协议支持:AMQP,XMPP, SMTP, STOMP | HTTP | ONS私有协议 | |
| 消息批量操作 | 支持 | 不支持 | 支持 | 不支持 | |
| 消息推拉模式 | Pull | 多协议, Pull/Push均有支持 | Pull | Pull, Push | |
| 保证消息至少消费一次 | 默认保证 | 保证 | 在消息有效期内,确保消息至少能被成功消费一次。 | 不保证(消费失败16次后丢弃) | |
| 消息回溯 | 支持 | 消费完即删除, 不支持回溯 | 消费完即删除, 不支持回溯 | 支持 | |
| HA | 支持replica机制, leader宕掉后, 备份自动顶替, 并重新选举leader(基于Zookeeper) | master/slave模式, master提供服务, slave仅作备份 | – | – | |
| 数据可靠性 | 上周的测试中, 使用Kafka作为消息中间件, 数据可靠, 并且有replica机制, 有容错容灾能力 | 可以保证数据不丢, 有slave用作备份 | 数据三重备份, 可靠性达10个9 (官方数据) | 99.99% (官方数据) | |
| QPS | 性能卓越, 详见下文Linkedin团队的测试 | 性能优秀, 详见下文Linkedin团队的测试 | 默认4000 | 默认5000 | |
| 持久化能力 | 磁盘文件, 只要磁盘容量够, 可以做到无限消息堆积 | 内存、文件,支持数据堆积,但数据堆积反过来影响生产速率 | 消息持久化默认有期限, 支持海量堆积 | ONS消息默认保留三天,支持海量堆积 | |
| 是否有序 | 多Client保证有序 | 若想有序,只能使用一个Client | 不保证有序 | 不保证有序 | |
| 事务 | 不支持, 但可以通过Low Level API保证仅消费一次 | 不支持 | 不支持 | 支持 | |
| 集群 | 支持 | 支持 | 支持 | 支持 | |
| 负载均衡 | 支持 | 支持 | 支持 | 支持 | |
| 管理界面 | 官方只提供了命令行版, Yahoo开源自己的Kafka Web管理界面Kafka-Manager | 较好 | 好 | 好 | |
| 部署方式 | 独立 | 独立 | Aliyun提供服务 | Aliyun提供服务,可以独立部署 |
总结
- 事务支持方面,ONS/RocketMQ较为优秀,但是不支持消息批量操作, 不保证消息至少被消费一次.
- Kafka提供完全分布式架构, 并有replica机制, 拥有较高的可用性和可靠性, 理论上支持消息无限堆积, 支持批量操作, 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次. 但是官方提供的运维工具不友好,开源社区的运维工具支持的版本一般落后于最新版本的Kafka.
- 目前使用的MNS服务,拥有HTTP REST API, 使用简单, 数据可靠性高, 但是不保证消息有序,不能回溯数据.
- RabbitMQ为重量级消息系统, 支持多协议(很多协议是目前业务用不到的), 但是不支持回溯数据, master挂掉之后, 需要手动从slave恢复, 可用性略逊一筹.
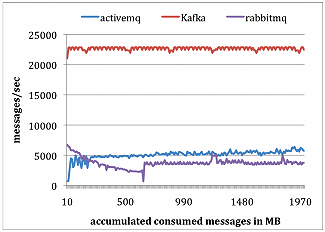
附: LinkedIn团队对Kafka, RabbitMQ, ActiveMQ的性能研究
生产者测试
LinkedIn团队在所有系统中配置代理,异步将消息刷入其持久化库。对每个系统,运行一个生产者,总共发布1000万条消息,每条消息200字节。Kafka生产者以1和50批量方式发送消息。ActiveMQ和RabbitMQ似乎没有简单的办法来批量发送消息,LinkedIn假定它的批量值为1。结果如下图所示:
消费者测试
为了做消费者测试,LinkedIn使用一个消费者获取总共1000万条消息。LinkedIn让所有系统每次拉请求都预获取大约相同数量的数据,最多1000条消息或者200KB。对ActiveMQ和RabbitMQ,LinkedIn设置消费者确认模型为自动。结果如下图所示
参考文档: